InformationSecurityPro
 Marcos Henrique
Marcos Henrique

OCR - Como extrair o Texto de uma Imagem?
O OCR Reconhecimento Óptico de Caracteres (Optical Character Recognition), é uma tecnologia usada para converter diferentes tipos de documentos, como imagens digitalizadas de texto impresso, arquivos PDF entre outros.
Neste artigo eu mostro como você pode realizar a extração do texto das imagens abaixo utilizando as bibliotecas: Tesseract OCR, EasyOCR e OCR Space.
Exemplos




Utilizando Tesseract OCR
01 - Passo
Realize o download do Tesseract e conclua a instalação.
Observações:
- Após a instalação pode ser necessário reiniciar o computador.
- Certifique-se de cadastrar o caminho de instalação do Tesseract nas Variáveis de Ambiente.
02 - Passo
Instale a biblioteca pytesseract
Pythonpip3 install pytesseract
03 - Passo
Código: ocr-img-pytesseract.py
Python
import pytesseract
from PIL import Image
def extrair_texto_imagem(caminho_imagem):
imagem = Image.open(caminho_imagem)
texto = pytesseract.image_to_string(imagem)
return texto
# Extrair Texto
caminho_imagem = 'Imagens\\ocr-01.png'
texto_extraido = extrair_texto_imagem(caminho_imagem)
print(texto_extraido)
Resultado
Avaliação:
🟢 Ótimo 🔵 Bom 🟡 Regular 🔴 Ruim
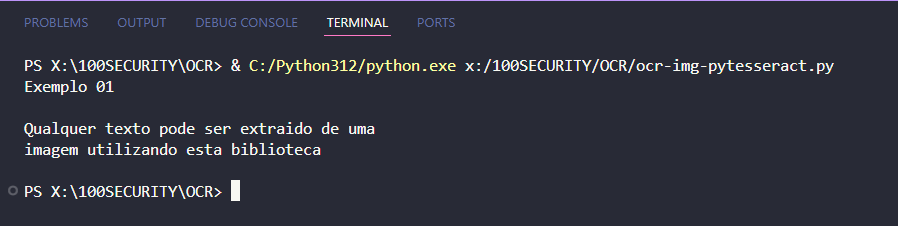
Exemplo 01 🟢
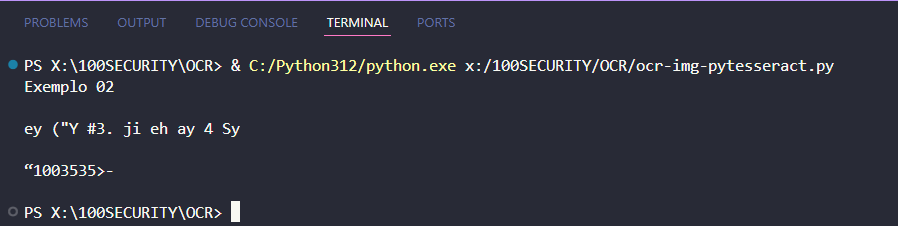
Exemplo 02 🟡
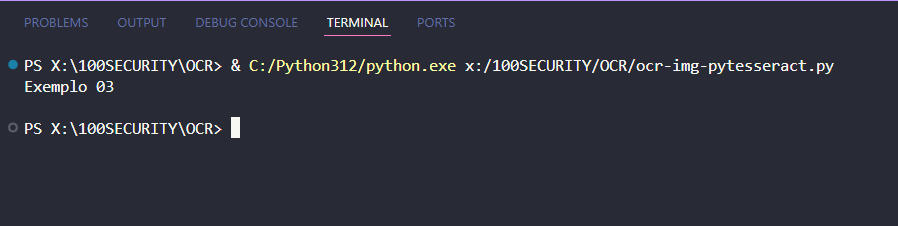
Exemplo 03 🔴
Exemplo 04 🟡

Utilizando EasyOCR
01 - Passo
Instale a biblioteca easyocr
Pythonpip3 install easyocr
02 - Passo
Código: ocr-img-easyocr.py
Python
import easyocr
def extrair_texto_imagem_easyocr(caminho_imagem):
reader = easyocr.Reader(['pt'])
resultado = reader.readtext(caminho_imagem)
texto = '\n'.join([elem[1] for elem in resultado])
return texto
# Extrair Texto
caminho_imagem = 'Imagens\\ocr-01.png'
texto_extraido = extrair_texto_imagem_easyocr(caminho_imagem)
print(texto_extraido)
Resultado
Avaliação:
🟢 Ótimo 🔵 Bom 🟡 Regular 🔴 Ruim
Exemplo 01 🟢

Exemplo 02 🔴

Exemplo 03 🟡

Exemplo 04 🟡

Utilizando OCR Space
01 - Passo
Instale a biblioteca requests e solicite sua API Gratuita no site https://ocr.space/OCRAPI
Pythonpip3 install requests
02 - Passo
Código: ocr-img-ocr.space.py
Python
import requests
def extrair_texto_ocr_space(api_key, imagem_ou_url):
url = "https://api.ocr.space/parse/image"
if imagem_ou_url.startswith('http://') or imagem_ou_url.startswith('https://'):
payload = {
'apikey': api_key,
'url': imagem_ou_url,
'language': 'por',
}
files = {}
else:
with open(imagem_ou_url, 'rb') as image_file:
img_data = image_file.read()
payload = {
'apikey': api_key,
'language': 'por',
}
files = {'file': img_data}
# Envia a requisição para a API
response = requests.post(url, data=payload, files=files).json()
texto = response['ParsedResults'][0]['ParsedText']
return texto
# Extrair Texto
api_key = '000000000000000' # INSIRA SUA API KEY AQUI!
url_imagem = 'https://www.100security.com.br/images/ocr-01.png'
texto_extraido_url = extrair_texto_ocr_space(api_key, url_imagem)
print("Texto extraído de URL:", texto_extraido_url)
Resultado
Avaliação:
🟢 Ótimo 🔵 Bom 🟡 Regular 🔴 Ruim
Exemplo 01 🟢

Exemplo 02 🔴
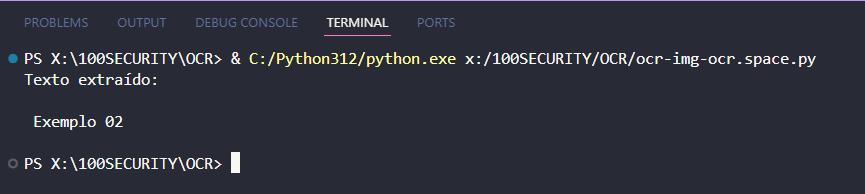
Exemplo 03 🔴
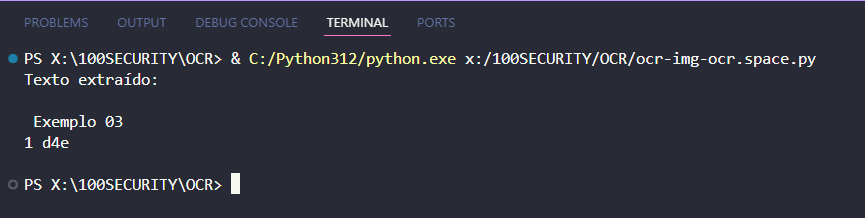
Exemplo 04 🟡
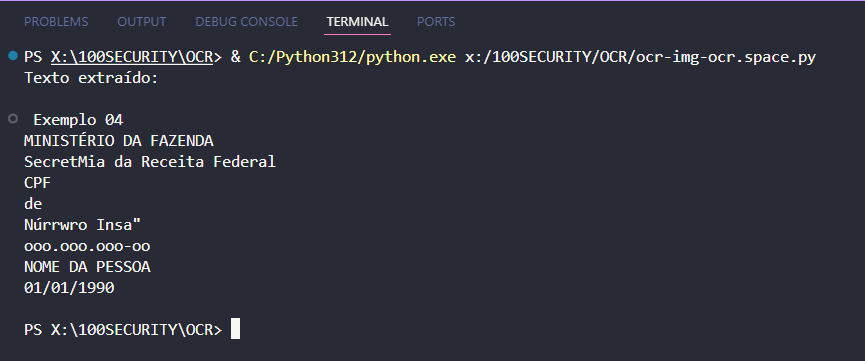
Alternativas Online
🌎 New OCR
🌎 XODO OCR
Extensões / Plugins
🎲 Chrome: Copyfish 🐟 Free OCR Software
🎲 Chrome: Editor de OCR - texto da imagem
🎲 Chrome: Captura de tela para texto (OCR) - Extrator de texto de imagem
🎲 Chrome: OCR - Image Reader
🎲 Chrome: Docsumo Free OCR Software
🎲 Chrome: Image Reader (OCR)

 São Paulo/SP
São Paulo/SP
















































